今天開始就要進入神經網路的世界啦!首先介紹的就是循環神經網路(Recurrent Neural Network, RNN)。RNN 是什麼呢?為什麼要用 RNN?這一切的解答必須要先回到 Deep learning 最初的樣子----前饋神經網路(Feedforward Neural Network, FNN)。FNN 是最簡單的神經網路模型,資料是單向傳輸的。input 經由輸入層通過隱藏層(hedden layer)再到輸出層,其中的神經元(neuron)之間沒有連接迴路存在。如下圖所示:
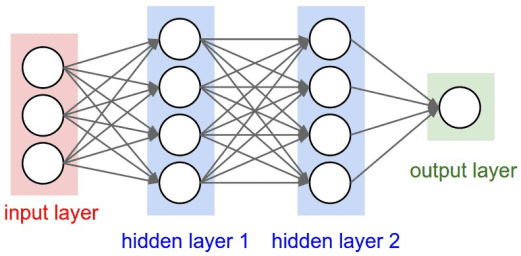
然而,這樣單純的神經網路有以下幾特缺點:
無法處理順序資料 (sequential data)
僅考慮當前輸入
無法記住以前的輸入
這些問題都能由 RNN 來解決,因為 RNN 可以處理順序資料,同時接受當前輸入和之前接收到的輸入,並且因為 RNN 有內部記憶體,所以 RNN 可以記住以前的輸入。
如圖所示:
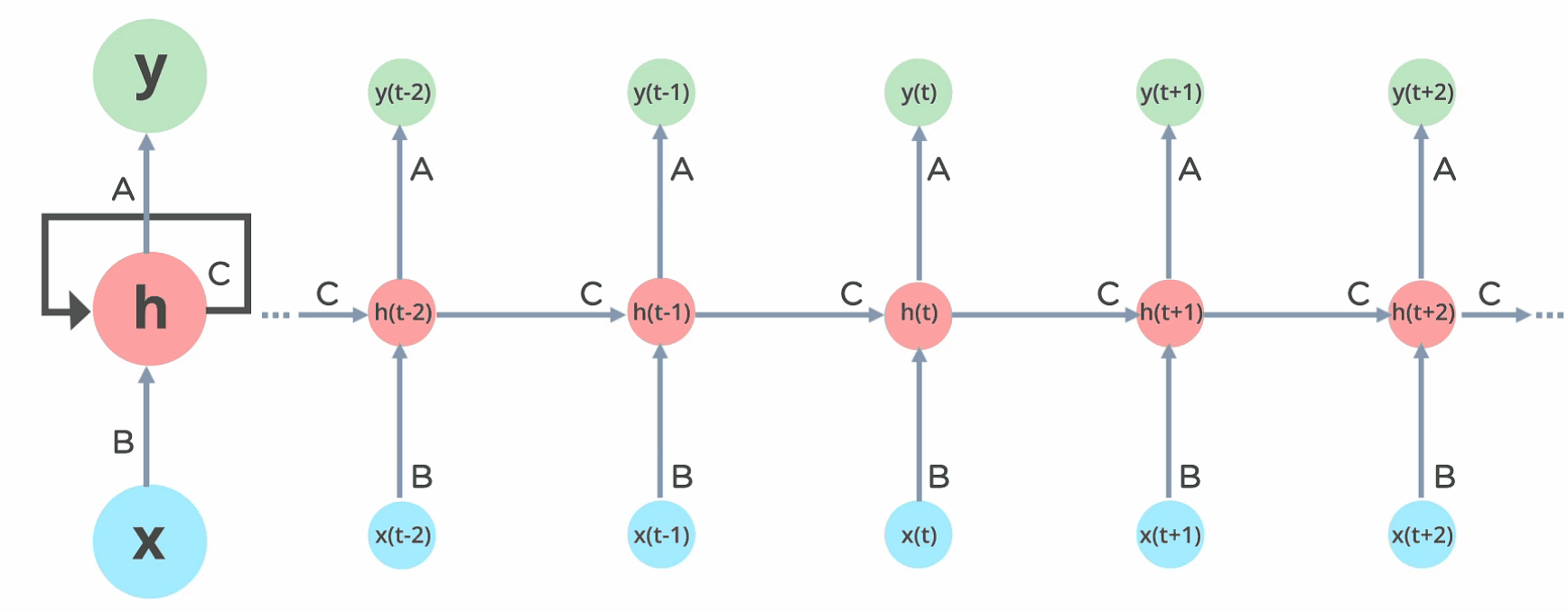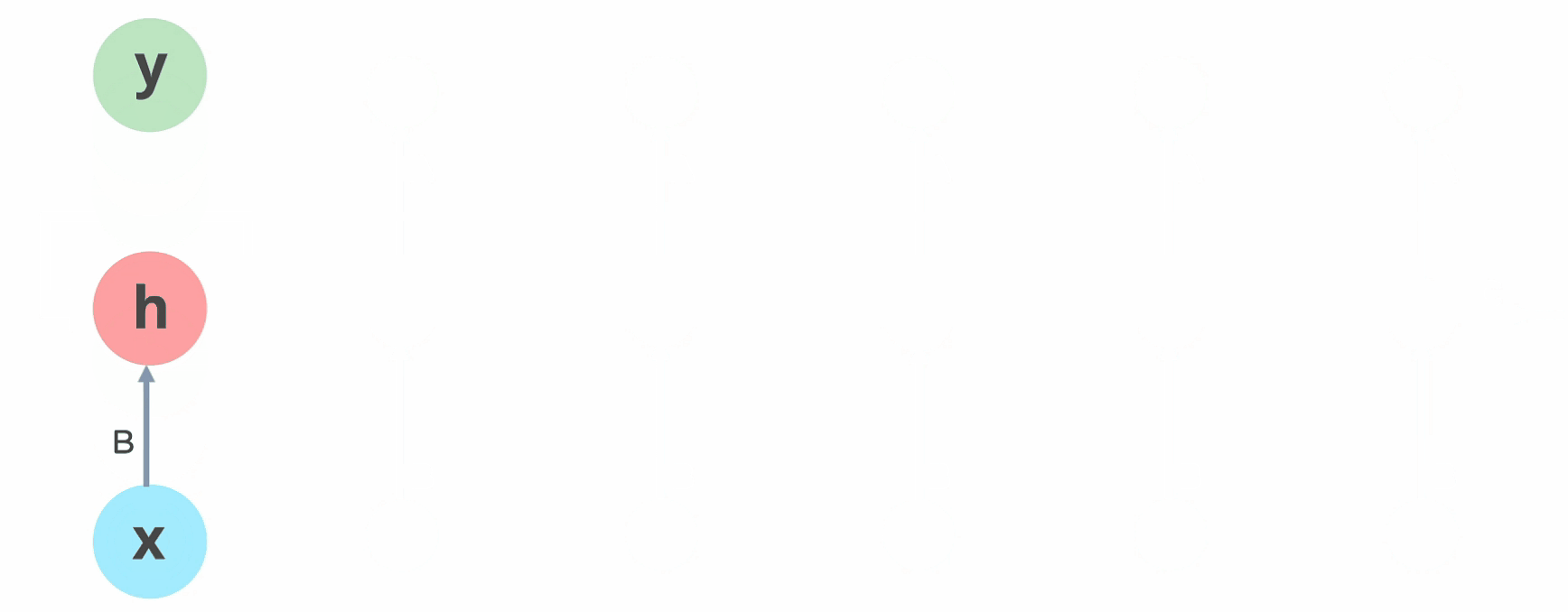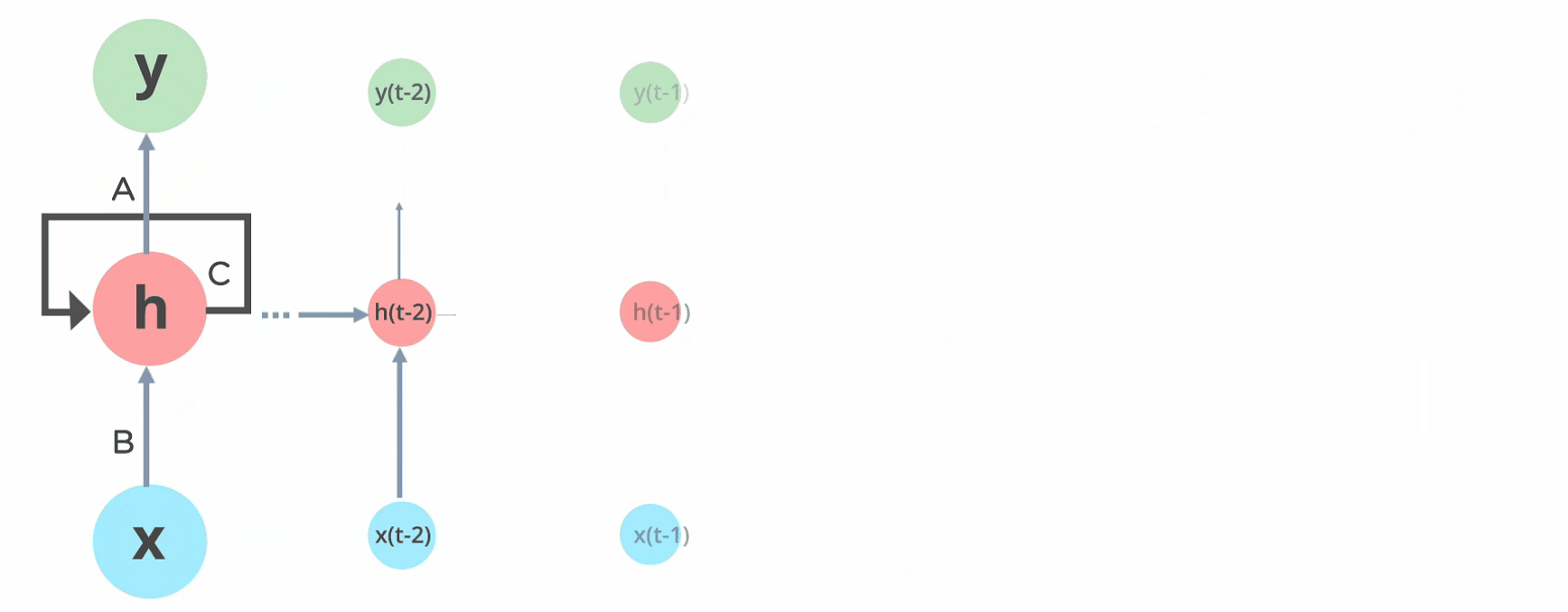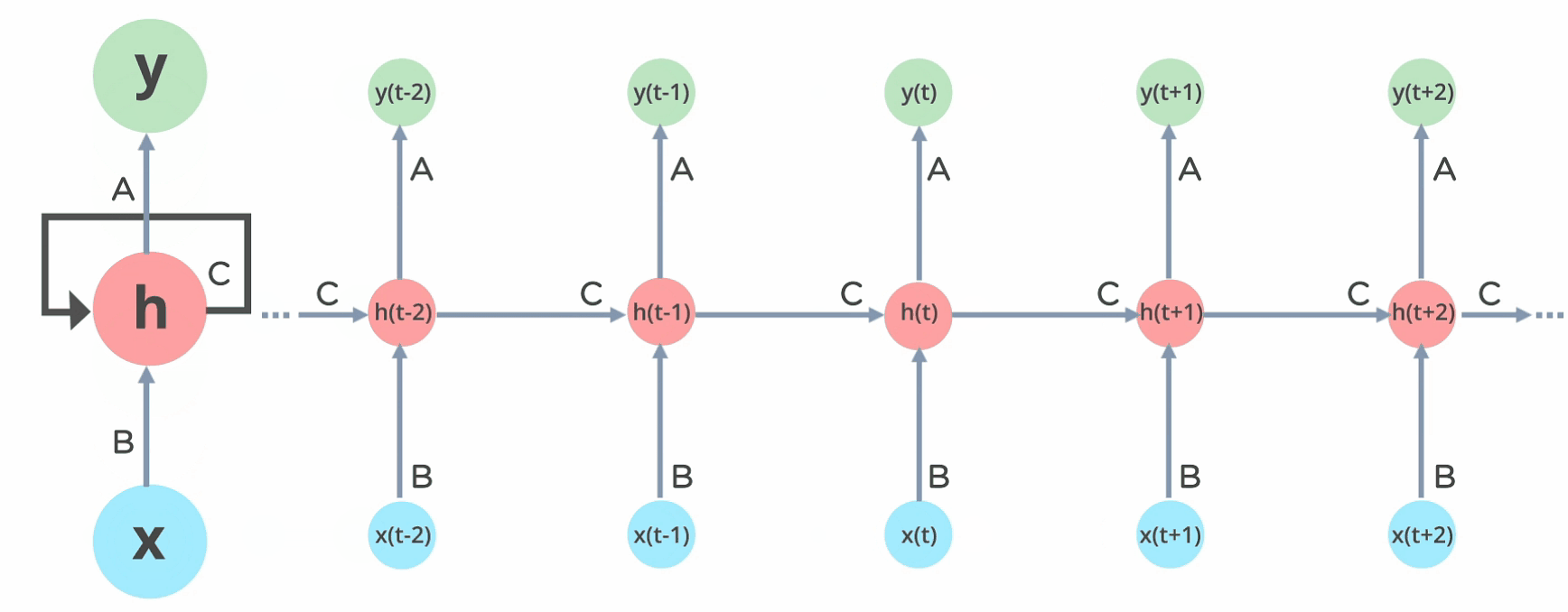
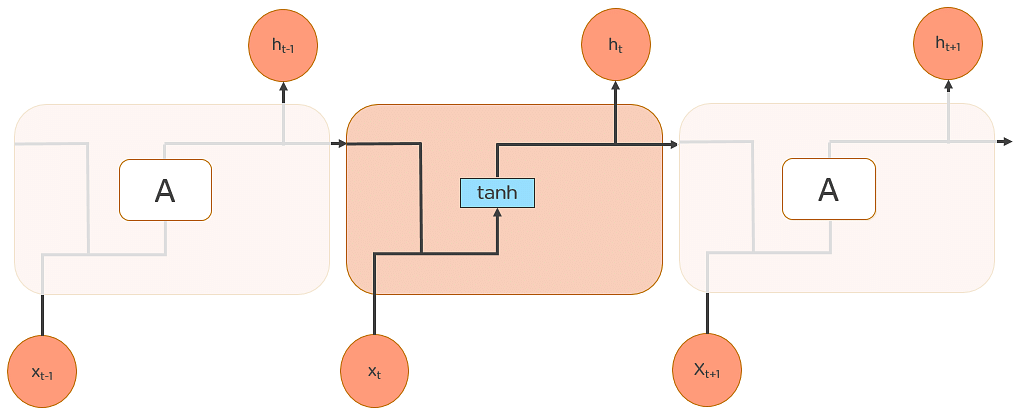
RNN 的 input 會通過 loop 循環到中間 hidden layer。
輸入層 'x' 接收神經網路的輸入並對其進行處理,將其傳遞到中間層 'h'。
中間層 'h' 可以由多個循環的 hidden layers 組成,每個 hidden layer 都有自己的激勵函數 (Activation function)、權重和偏差。也就是說如果你希望你的神經網路是有記憶的,且每一層之間參數會互相影響,那就該選擇 RNN。
3.RNN 將不同的激勵函數、權重和偏差進行標準化(standardize),讓每個循環的 hidden layer 具有相同的參數。 也就是說整體而言 RNN 只會建立一個 hidden layer,再依據需要循環多次,才會有所謂多個循環的 hidden layers。(圖中向右側延伸的每一個 hidden layer 都是 'h' 這一個循環的 hidden layer 展開的樣子)
在 NLP 中 RNN 是非常常使用的神經網路,主要是因為分析語言必須考慮前後文之間的關聯,故採用有記憶的 RNN 是較佳的選擇。其中的應用包含機器翻譯、文本探勘與情緒分析等等。
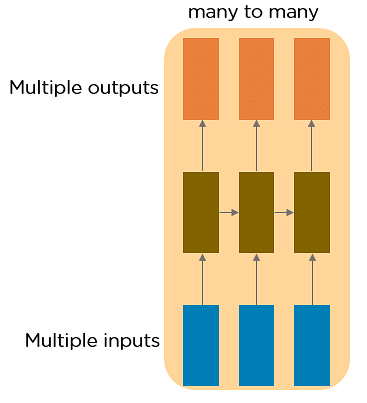
RNN 又可分為 4 種類型:
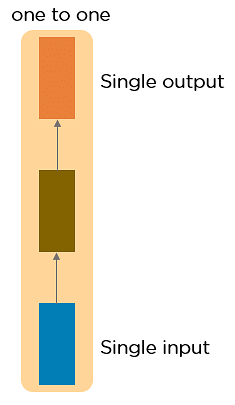
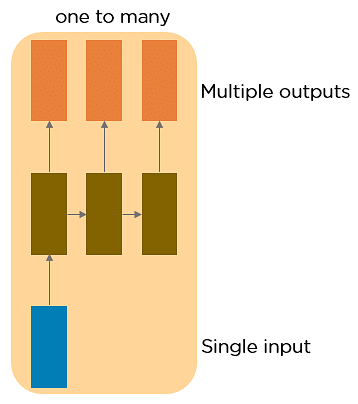
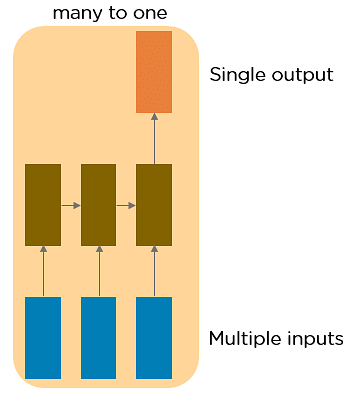
梯度消失問題會出現在以梯度下降法和反向傳播訓練人工神經網路的時候。在每次訓練的迭代中,神經網路權重的更新值與誤差函數的偏導數成比例,然而在某些情況下,梯度值會幾乎消失。然而,梯度攜帶 RNN 中使用的資訊,當梯度變得太小時,參數更新變得不重要,會讓長序列資料的學習變得困難,甚至神經網路可能完全無法繼續訓練。
梯度爆炸正好相反,當最初的權重值(w)過大時,w 乘以激勵函數的導數都大於 1 。這樣會讓神經網路前面層比後面層梯度變化更快,梯度爆炸就會因此產生。
而處理梯度問題的最流行和最有效的方法即長短期記憶網路(Long short-term memory, LSTM)。而了解 LSTM 之前必須先知道何謂長期依賴(Long-Term Dependencies)。
假設你想預測一篇文章中的一個單詞:「雲在____。」
最明顯的答案是 「天空」。我們不需要任何進一步的上下文來預測上述句子中的最後一個單詞。
但若換成這句話:「我在台北的公司待了 35 年,退休離開 _____ 之後,我想要出國去看看。」
在這裡,空格內填入任何一個地點都可以,而顯然最佳的答案「台北」是需要透過上下文,才能夠較好的預測。不過藉由這個句子會發現,若需要上下文的加入,相關資訊與所需資訊之間的差距可能會變得很大。而 LSTM 可以解决這樣的問題。
LSTM 是一種特殊的 RNN,能够通過長時間記憶來學習長期依賴資訊。
所有 RNN 都是重複的神經網路模組,進而形成鏈的形式。 在 standard RNN 中,此重複模組的結構非常簡單,如圖所示:
LSTM 也有鏈狀結構,但重複模組的結構略有不同。它不是只有一個神經網路層,而是四個相互作用的層在進行訊息處理。如圖所示:
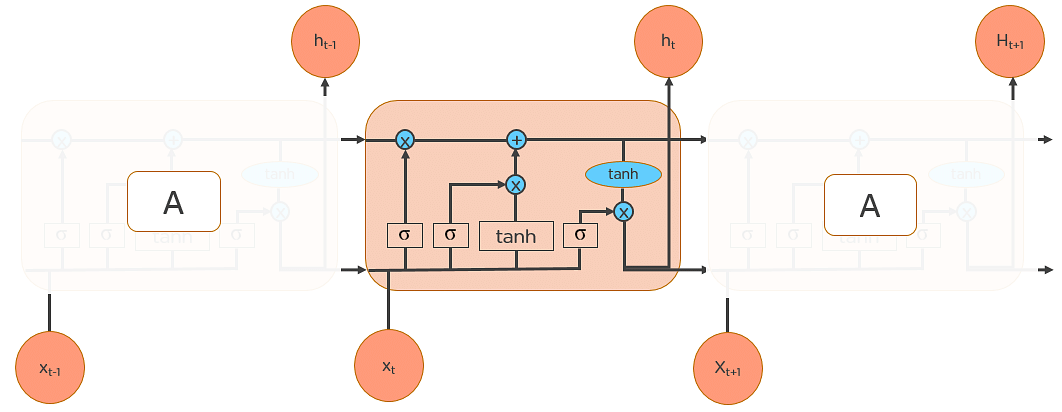
因此,我們將這樣略為複雜的結構放置到 standard RNN 之中就能改善前面所提到的問題了!
建構 LSTM 有 3 個主要要思考的步驟與方向:



看完這麼多的介紹,我們來實作一下,預測股價吧!
使用 Google_Stock_Price_Train:(https://www.kaggle.com/datasets/akram24/google-stock-price-train
)
和 Google_Stock_Price_Test:(https://www.kaggle.com/datasets/akram24/google-stock-price-test
) 資料集
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
dataset_train = pd.read_csv('/content/Google_Stock_Price_Train.csv')
training_set = dataset_train.iloc[:, 1:2].values
# 資料 scaling
from sklearn.preprocessing import MinMaxScaler
sc = MinMaxScaler(feature_range = (0,1))
training_set_scaled = sc.fit_transform(training_set)
# 從 scaled data 製作訓練集
X_train = []
y_train = []
for i in range(60, 1258):
X_train.append(training_set_scaled[i-60:i, 0])
y_train.append(training_set_scaled[i, 0])
X_train, y_train = np.array(X_train), np.array(y_train)
# Reshaping
X_train = np.reshape(X_train,(X_train.shape [0], X_train.shape [1], 1))
# Importing the Keras Libraries and packages
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from keras.layers import Dropout
# 啟用 RNN
regressor = Sequential ()
# 添加 LSTM layer 和要丟掉的資訊設置,會發現這邊就是一個 loop
regressor.add(LSTM(units = 50, return_sequences = True, input_shape = (X_train.shape [1], 1)))
regressor.add(Dropout (0.2))
regressor.add(LSTM(units = 50, return_sequences = True))
regressor.add(Dropout (0.2))
regressor.add(LSTM(units = 50, return_sequences = True))
regressor.add(Dropout (0.2))
regressor.add(LSTM(units = 50))
regressor.add(Dropout (0.2))
# output layer
regressor.add(Dense (units = 1))
regressor.compile(optimizer = 'adam', loss = 'mean_squared_error')
regressor.fit(X_train, y_train, epochs = 100, batch_size = 32)
# 進行測試
dataset_test = pd.read_csv('/content/Google_Stock_Price_Test.csv')
real_stock_price = dataset_test.iloc[:, 1:2].values
# 獲得 2017 年股價預測
dataset_total = pd.concat ((dataset_train['Open'], dataset_test['Open']), axis = 0)
inputs = dataset_total[len(dataset_total) - len(dataset_test) - 60:].values
inputs = inputs.reshape(-1,1)
inputs = sc.transform(inputs)
X_test = []
for i in range(60, 80):
X_test.append(inputs[i-60:i, 0])
X_test = np.array(X_test)
X_test = np.reshape(X_test, (X_test.shape[0], X_test.shape[1], 1))
predicted_stock_price = regressor.predict(X_test)
predicted_stock_price = sc.inverse_transform(predicted_stock_price)
# 結果視覺化
plt.plot (real_stock_price, color = 'red', label = 'Real Google Stock Price')
plt.plot(predicted_stock_price, color = 'blue', label = 'Predicted Google Stock Price')
plt.title ('Google Stock Price Prediction')
plt.xlabel('Time')
plt.ylabel('Google Stock Price')
plt.legend ()
plt.show()
輸出結果為:



 iThome鐵人賽
iThome鐵人賽